By Rahul Ghosh, Senior Tech Lead
25th July, 2025
Bizom uses MySQL as its primary database to support daily operations and meet the needs of its customers. Each day, millions of requests come in, making hundreds of thousands of transactions across the customer base. With the ever-growing list of features and supports, another item grew parallely. Yes, it’s bugs!
Now, the challenge with bugs is that they need to be reproducible consistently, in order for the developers to fix them permanently. Debugging directly on a production server is generally a big red flag, and for good reason. Like most teams, we follow this best practice strictly and only consider it in rare, justifiable emergencies.
Bizom has a staging environment, which is a copy of the production environment with sensitive information of the customers masked. This is used by the developers to identify and fix bugs, along with verifying the new feature set that is built. Other teams, like product and sales, use the staging environment for demo purposes. Sometimes the customers themselves use this environment before confirming the go-live.
In one of the earlier hackathons, one of the teams in Bizom developed a cloning solution, which would leverage the MYSQL dump and import technique, to copy the entire database and apply masking of sensitive data points of the customer. As for the code, the production environment commit would be checked, and the same codebase would be pushed to the staging server for the respective customer.
Our platform is built on a multi-tenant architecture, a design choice that offers significant benefits in terms of both scalability and security. At present, the total database size has reached around 20TB. The previous solution served us well for the past couple of years, but as the database has grown significantly in size, we’re starting to hit some limitations. Now, to clone the individual schemas to the staging environment, we faced the following challenges:-
Bug fixing became a slow process because it took time to reproduce and confirm issues on the staging environment. Until that step was done, developers couldn’t really make progress on resolving them.
Looking at this problem, we identified a couple of ways to solve the challenges. Some of them are listed as follows:-
We focused heavily on these three main strategies, each of which went through several rounds of ideation and refinement.
Option 4 would be ideally the best choice, but it had many limitations for our system. Some of them being that all the tables would have to have an identifier(id, time-range) in order to effectively copy the data, with the index being present on the identifier alone. This was not present in all the tables, and to apply to all of them would be time consuming. Another challenge involves handling foreign key constraints. For instance, an invoice record may reference an order that lies outside the defined scope of the delta sync, resulting in referential integrity issues during the cloning process. Third, other teams used the same schema in the staging environment for demo purposes. Creating a conflict of data points would hardly be beneficial to our cause. Consistency of data is highly desirable.
The second and third options also looked good, but require extra maintenance of the filtered table list per schema. A major drawback is handling the foreign key constraints across multiple tables. This would lead the developers to effectively debug the cloning procedure, not the bug that they were supposed to solve. When new tables are added, developers need to ensure this new table is handled accordingly.
Option 1 seems the best choice, and the tool that we wanted to go with is MyDumper. One recurring challenge was the continuous growth of data. In the absence of a consistent archival strategy across all tables, core transactional data kept expanding rapidly. As a result, the scalability of this solution was inherently limited—even in the near term. And while it might work for a single customer, applying it across all customers would be unsustainable.
The primary goal is to enable safe and efficient debugging in the production environment without compromising data integrity. The key challenge lies in debugging live systems, where unintended writes or overwrites could corrupt critical data—an unacceptable risk for Bizom and its customers.
To address this, we need a solution that allows developers to inspect and troubleshoot issues in real-time while ensuring that no accidental modifications occur. This requires implementing safeguards that prevent unintended data changes while still providing comprehensive visibility into system behavior.
Talking to our developers and QA team, we found out the following:-
Given the considerations above, it became evident that a separate environment was needed—one that could be accessed by both developers and the QA team. Since real-time, up-to-the-minute data wasn’t a requirement, designing and implementing this environment became significantly more straightforward.
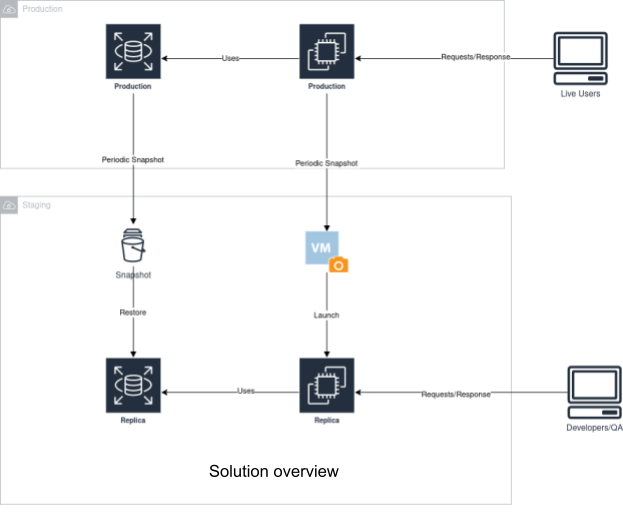
Here’s how:-
These steps create a new setup, where the developers and QA can safely debug and reproduce the bugs, respectively. These gave the following benefits:-
The only trade-off with this solution is the cost. Given the volume of data involved, the monthly expense represents a significant investment for a company of our size. However, we made a strategic decision to move forward, anticipating that it would alleviate a key bottleneck: developer productivity. By enabling faster debugging and issue resolution, we believe the time saved will translate into long-term cost savings for Bizom.
The initial implementation of this solution was focused solely on the web platform. Subsequent iterations introduced enhancements that improved developer experience and usability. Given the clear benefits, the solution was eventually extended to support mobile applications as well.
However, cost optimization remained a key concern. We identified an opportunity to reduce expenses further by evaluating the nature of the database usage. Since the database server was being recreated daily and the previous instance purged, the data was inherently temporary, offering no long-term value in persisting it. Additionally, by analyzing developer login patterns, we gained insights into actual usage times, which further informed our optimization strategy.
A straightforward solution emerged: the new setup would be provisioned only on weekdays (Monday to Friday) and remain inactive over the weekends. Based on observed usage patterns, the setup is automatically torn down at 11:00 PM IST each night and re-initialized the following morning — striking a balance between availability and resource efficiency.
With this approach, the total cost of the setup is reduced, resulting in savings of nearly 49%. This not only brings significant cost efficiency to the organization but also provides developers with the added benefit of a fresh, dedicated environment for debugging and issue resolution.
Internal metrics indicate a 20% improvement in the average bug lifecycle turnaround time. Additionally, monthly clone request numbers have decreased by approximately 20–30%, reflecting greater efficiency in issue resolution and workflow management.

