By Rahul Ghosh, Senior Tech Lead
25th July, 2025
We’re excited to share how we recently tackled a significant performance challenge to make a key feature even better for our users.
Our platform includes a powerful Auto Replenishment System (ARS). This module is a game-changer for inventory management, helping brands effortlessly place orders. It works by analyzing historical sales data, looking back anywhere from 30 days to six months, to provide intelligent, data-driven recommendations. This means our customers can keep their shelves stocked and their businesses running smoothly, all based on smart insights.
However, as the underlying formulas driving these recommendations grew more sophisticated, we noticed a bottleneck: the time it took to fetch the necessary data started increasing significantly, sometimes exceeding five minutes. While this was understandable, given the massive volumes of transactional data (think orders and sales) that our system handles daily, we knew long wait times weren’t acceptable. Our goal is always to deliver a seamless and efficient experience, especially when clients are making critical ordering decisions.
Our goal is always to deliver a seamless and efficient experience, so we made it a priority to optimize this process. We’re committed to ensuring our clients get the recommendations they need, precisely when they need them, without any frustrating delays.
We looked into the causes of the delay. After analyzing the situation, we found that the queries were taking too long to execute and load the data. Bizom uses a MySQL database with the InnoDB engine for data storage. We also noticed that indexes were applied to certain columns, particularly those used for filtering data. Given that MySQL is known for its performance with indexes and has a proven track record, we were left wondering why it was taking so much time.
Our deep dive revealed the culprit. The specific queries in question involved a composite index on both a date column and an ID column. These filters were applied in a particular order: first, a date range using a BETWEEN clause, followed by a search on an “outlet_id” using an “IN” clause with a large number of values.
This combination effectively translated into a highly inefficient query pattern behind the scenes. Imagine asking the database to do something like this for every single outlet:
WHERE (date BETWEEN “start_date” AND “end_date” AND outlet_id = ‘first_value’) OR (date BETWEEN “start_date” AND “end_date” AND outlet_id = ‘second_value’) OR …
While each individual OR condition could leverage the index, combining a range scan with a massive IN clause across many OR conditions was forcing the database to work much harder than necessary. The MySQL optimizer decided to bypass the index and perform a full table scan, which rendered the indexes ineffective. For smaller IN clauses, the indexes were successfully utilized. This insight was key to devising our solution.
We’re constantly striving for peak performance, and to that end, we’ve been implementing key optimizations to ensure our system remains fast, responsive, and robust as we continue to grow. Our latest focus has been on refining how our database handles complex queries.
A crucial insight from our recent work involved the common IN clause, especially when dealing with a large number of values. We discovered that by intelligently splitting the number of values in the IN clause into smaller, more manageable groups, we could dramatically improve query efficiency. This strategy allows the database to more effectively utilize its indexes, leading to significantly faster data retrieval. It’s a prime example of how small, targeted adjustments can lead to substantial performance gains, ensuring a smoother experience for all our users.
While we had a promising solution, we quickly hit a roadblock. Our initial approach involved executing data queries sequentially. This meant each new query had to wait for the one before it to finish, and we also incurred overhead from repeatedly establishing database connections.
Our testing confirmed that this sequential method actually led to a significant performance degradation. In fact, it proved to be even less efficient than some of the less-than-ideal alternatives we had considered, such as using an overly long list of values within a single IN clause. This observation highlighted the critical need for a more concurrent strategy to truly unlock the performance gains we were targeting.
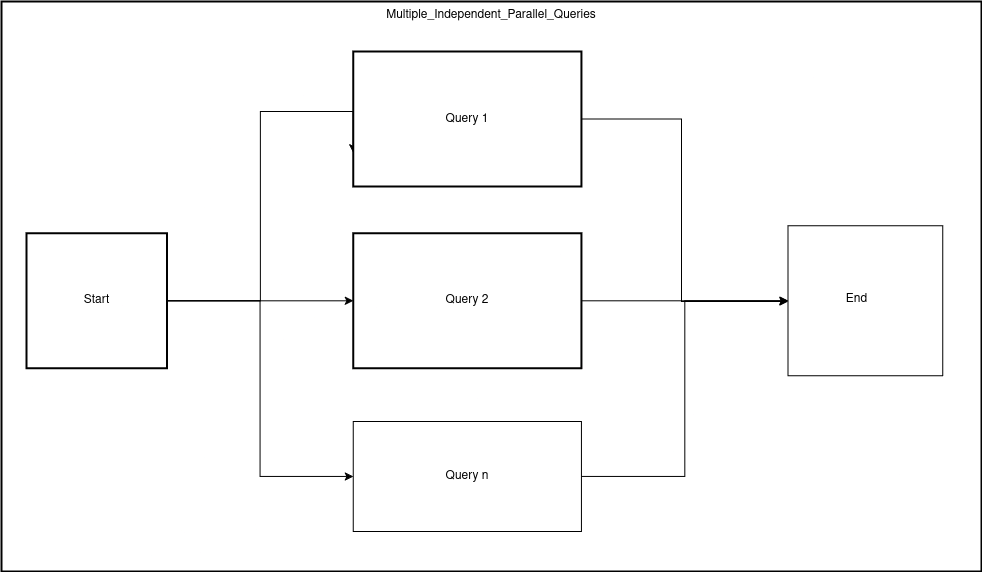
Given that our application is developed in Java, a language with excellent built-in support for concurrent processing, we saw a clear path forward. Our engineering team went to work, not just on the application side but also deeply considering how MySQL would handle these parallel requests.
Our solution involved restructuring the queries to enable the application to run multiple independent queries concurrently. Instead of one monolithic, slow query, we break it down into smaller, optimized chunks. This allows MySQL to leverage its own internal mechanisms for handling concurrent requests more efficiently.
Crucially, we also focused on careful tuning of the parallelism limits within our application. Overwhelming the database with too many concurrent queries can be just as detrimental as running them sequentially. Our goal was to find the “sweet spot” – enough parallel execution to significantly speed up data retrieval without causing resource contention or stability issues on the MySQL server itself.
Upon deploying our latest optimizations to production, we immediately saw significant reductions in data load times.
These improvements mean our users can access the information they need quickly, enhancing their overall productivity.
Now that’s a major efficiency gain!

