By Samarth Patel, Senior Software Engineer
25th July, 2025
Search is a fundamental part of the Bizom platform — whether it’s a salesman searching for products during a field visit, or internal teams managing catalogs. But building an effective search system is far more complex than just matching keywords.
At Bizom, we operate in the real world of FMCG and retail distribution, where users interact with the system in diverse, sometimes unpredictable ways. For instance, a retailer might type “wafar” instead of “Wafers,” or search for “namkeen” expecting a list of snacks. Some users mix Hindi and English (e.g., “paani” for water), while others refer to products by nicknames or local aliases. A rigid, exact-match keyword search simply doesn’t cut it in such environments.Search is a fundamental part of the Bizom platform — whether it’s a salesman searching for products during a field visit, or internal teams managing catalogs. But building an effective search system is far more complex than just matching keywords.
Improving search isn’t just a technical challenge — it’s a business imperative. Poor search can mean lost orders, longer call times for support teams, and frustration for field users trying to complete a simple task. Our goal was to make search intuitive, forgiving, and intelligent — regardless of how a user chooses to express their need.
To solve the search challenges we faced, we adopted a layered approach — starting with making search fault-tolerant using fuzzy logic, and gradually moving toward understanding the intent behind search queries using semantic techniques.Improving search isn’t just a technical challenge — it’s a business imperative. Poor search can mean lost orders, longer call times for support teams, and frustration for field users trying to complete a simple task. Our goal was to make search intuitive, forgiving, and intelligent — regardless of how a user chooses to express their need.
Fuzzy search makes search more forgiving by correcting small errors in the user’s query. It uses techniques like Levenshtein Distance (edit distance) to match terms that are close enough to the actual data.
For example distance between: mesala wafar (user’s input) and masala wafer (actual item name) is 2. That is by editing two characters the target name can be achieved.
While fuzzy search fixes spelling issues, it can’t help when a user searches with a related concept instead of the exact word. That’s where semantic search becomes essentialFuzzy search makes search more forgiving by correcting small errors in the user’s query. It uses techniques like Levenshtein Distance (edit distance) to match terms that are close enough to the actual data.
For example distance between: mesala wafar (user’s input) and masala wafer (actual item name) is 2. That is by editing two characters the target name can be achieved.
Even if the word “namkeen” isn’t in the product name, we want to return items like: Masala Wafers, Bhujia etc.
To do this, we use embedding models to convert both search queries and product names into high-dimensional vectors that represent meaning. Then, using vector similarity search, we find the most relevant matches — even across synonyms, aliases, or category names.
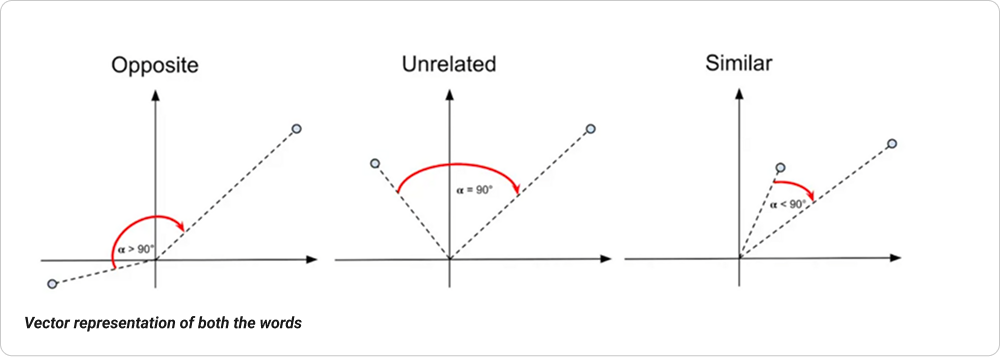
Vector representation of both the words
This allows the system to “understand” that “namkeen” is related to “bhujia” and “Wafers” even when the keywords don’t match directly.
We noticed users often typed in Hinglish — like “paani” for water or “namkeen” for snacks. While techniques like transliteration or multilingual embeddings were considered, we avoided overcomplicating things.
These methods are costly to implement and maintain, and given our finite, well-defined catalog, they were unnecessary. Instead, we adopted a simple and effective synonym-based approach — manually mapping common Hinglish terms to product keywords.
Vector representation of both the words
This allows the system to “understand” that “namkeen” is related to “bhujia” and “Wafers” even when the keywords don’t match directly.
Examples:
This lightweight solution worked well for our use case without adding model complexity.
Once we had finalized our approach — combining fuzzy search, semantic understanding, and Hinglish synonym support — we focused on building an architecture that was both scalable and maintainable.
OpenSearch served as the core of our search infrastructure, powering both traditional keyword-based search and semantic vector-based retrieval.
To streamline indexing, we used OpenSearch ingestion pipelines to apply a series of text transformations before data was stored. These transformations included steps like: Lowercasing and normalization, Synonym expansion (including Hinglish mappings), Removing special characters or stop words.
For semantic search, we went a step further by integrating embedding models directly into the pipeline, allowing us to vectorize product names and descriptions at index time. This eliminated the need for separate preprocessing jobs and ensured our vector data stayed in sync with the source.
This built-in pipeline support made our search system more maintainable and scalable without introducing external ETL complexity.
Logstash for Data Ingestion and Syncing
To sync our data from MySQL into OpenSearch, we used Logstash as the pipeline tool. Our setup ensures:
This near real-time syncing ensures that any updates to product data are quickly reflected in the search results without manual intervention or delays.
One of the key decisions we made was to maintain separate indexes for fuzzy and semantic search.
Not all search use cases require semantic understanding. For example, when a user types a product code or a highly specific name, fuzzy search is more than sufficient. On the other hand, broader or more generic queries like “namkeen” or “cold drink” benefit from semantic context.
By creating separate indexes, we were able to:
This also allowed us to apply different refresh strategies, analyzers, and embeddings depending on the nature of the index — giving us much more control without overengineering the system.
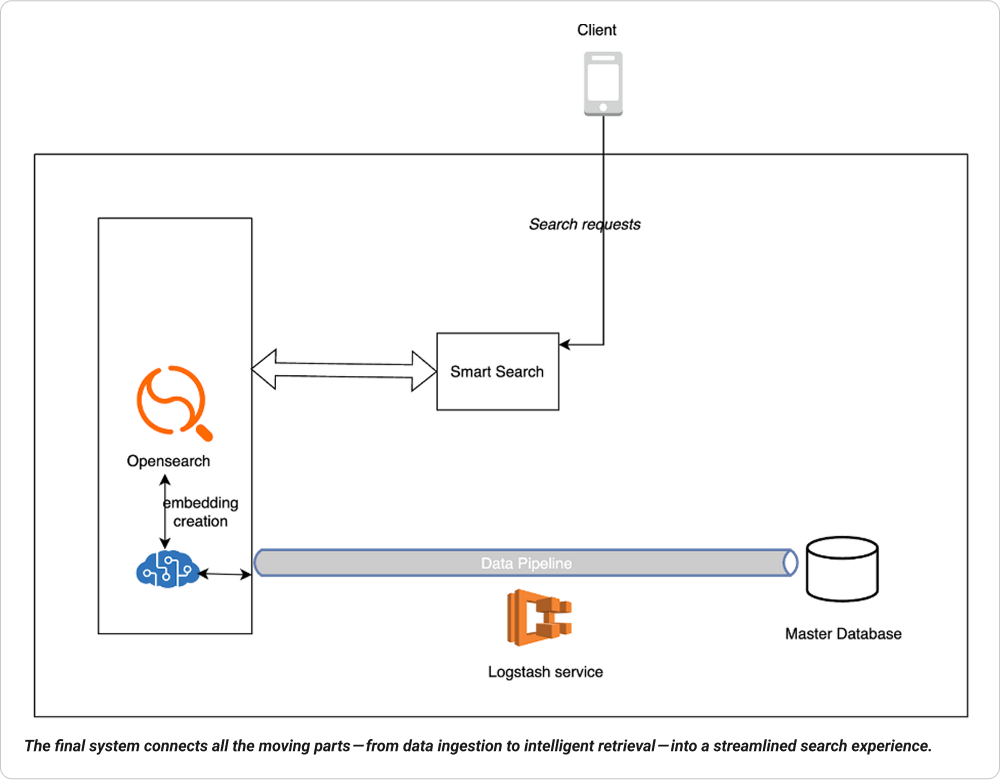
This architecture gave us flexibility to optimize for different query types, while keeping the system simple, efficient, and easy to extend.
Here’s how the flow works:
Client Interaction: End-users trigger search from the client app, which gets routed through the smart search layer to fetch the most relevant results.
We built a smart, efficient search system by combining fuzzy search, synonym-based Hinglish support, and selective semantic search. Given our well-defined catalog, we avoided overengineering and focused on practical solutions.
With OpenSearch for search and vector storage, Logstash for syncing with MySQL, and custom pipelines for text transformation and embeddings, our setup is both cost-effective and scalable — ready to support future needs

